I had the opportunity to present on Hyperlocal root and the LocalRoot project at sdns://2021 last week
I’ve written and presented about Hyperlocal root aka RFC 8806 in the past. In the context of privacy, Hyperlocal root does provide a possible solution to the problem,
Prevent snooping by third parties of requests sent to DNS root servers
RFC8806
Aside from that, faster negative responses to non-existent domains eliminates junk to the root
I did a quick check with Google Chrome 92.0.4515.131 and oddly enough I am still seeing this behaviour,
Aug 16 09:03:24 unbound[1:0] info: 192.168.100.4 ckgydztukkdsta. A IN
Aug 16 09:03:24 unbound[1:0] info: 192.168.100.4 lubdcupibujjne. A IN
Aug 16 09:03:24 unbound[1:0] info: 192.168.100.4 ltvlataieb. A IN
This will need further researching and debugging which I will save for another post.
A big thank you to Frank for organising sdns://2021 and also to folks from Quad9 for their help.
For some reason as can be seen in the video, presentation is stuck at a specific slide, the PDF can be found here
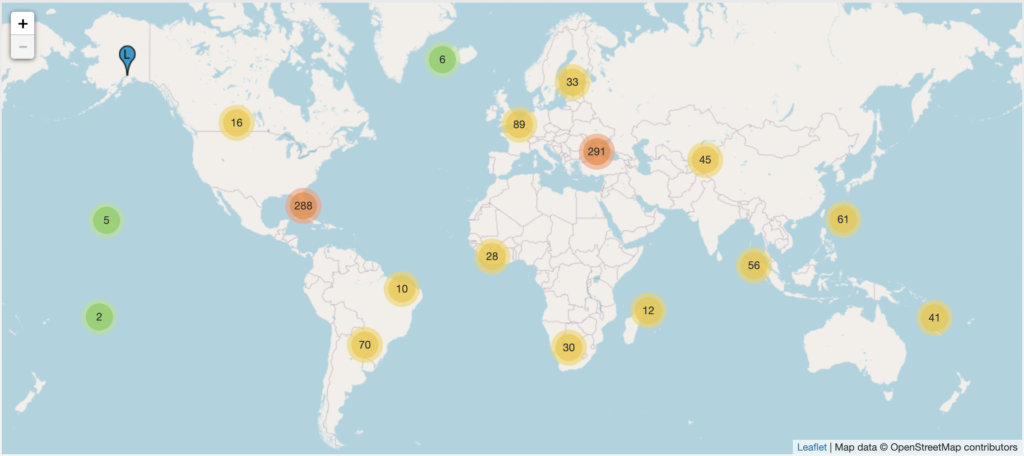
Image shows the locations of the root server IP Anycast instances. Source: https://root-servers.org/
Current State of DNS Root Servers
The DNS root server system uses IP Anycast.There are 13 root server operators with a total of 1084 instances all over the world. Let’s look at some of the problems in the context of the root server system,
Decrease the round trip time to the root servers
The round trip time to the root servers is dependent on multiple factors. Availability of a root server instance within the country and optimal routing. While the first can be addressed by installing an instance of the root server in a country, the second one is a bit hard to address. Routing determines whether the traffic to the root server from the last mile will reach the instance which is local or take the transit route to an instance outside the country.
If the traffic is transiting outside the country, the result is increased latency and poor performance in the context of DNS resolution.
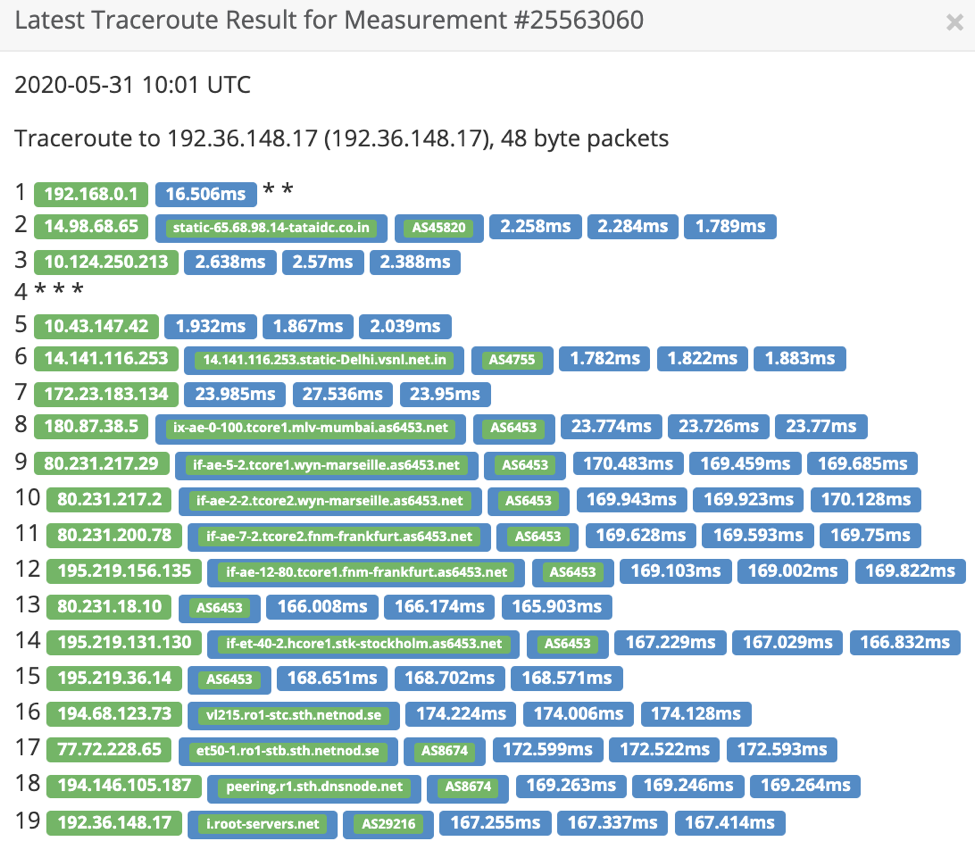
Case in point, in the context of India, Netnod which is a root server operator managing the i-root-servers.net has an Ancast IPv4 node in Mumbai.
A traceroute from AS9498 to i.root-servers.net shows that traffic is not hitting the local instance but taking the transit route.
traceroute from AS9498 to i.root-servers.net The above image has been taken from a RIPE Atlas measurement.
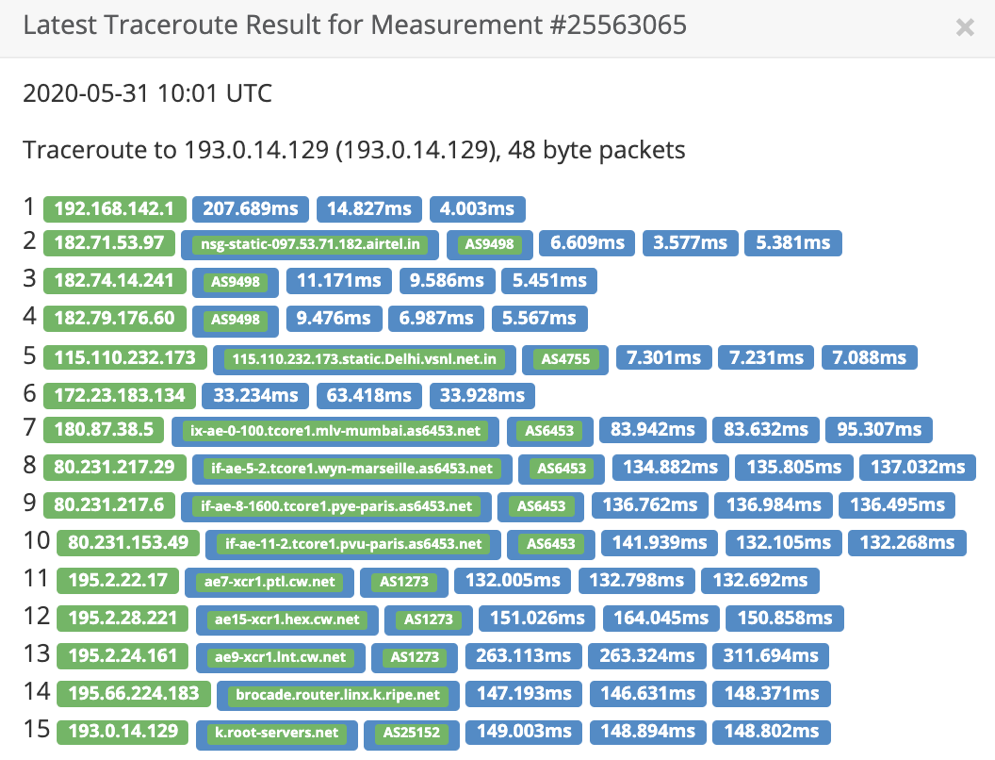
Similarly, RIPE NCC is the root server operator managing the k.root-servers.net. Again, in the context of India, there is an Anycast node IPv6 node in Mumbai and Noida.
A traceroute from AS9498 to k.root-servers.net shows that traffic is not hitting the local instance but taking the transit route.
traceroute from AS9498 to k.root-servers.net The above image has been taken from a RIPE Atlas measurement.
If you aren’t aware of the RIPE Atlas project, check the earlier post
Prevent snooping of queries
In the case of traditional DNS or DNS over 53( Do53), the traffic is unencrypted. In response to the privacy concerns and to secure DNS traffic between the client and the recursive resolver, IETF standardised DNS-over-HTTPS (DoH) and DNS-over-TLS (DoT). While both of the protocols secure the communication between the client and the recursive resolver, traffic between the recursive resolver and the root servers is still in the open i.e unencrypted.
Faster negative responses to queries for non-existent domains
The recent study by ICANN OCTO reveals that a vast majority of the queries to the root servers are for names which do not exist in the root zone. By providing faster negative responses to non existent domains to the stub resolver, eliminate sending the junk queries to the root servers entirely.
Increase the resiliency of the root server system
In the context of DNS, the primary intention of using IP Anycast is to have the topologically closest server provide the answer. This model fails if there is suboptimal routing as seen in the examples of traceroute to the root servers earlier.
The additional benefit of using IP Anycast is that considering optimal routing, in the event of a DDoS attack, the impact is limited in effect as it gets confined to certain areas. In the past, IP Anycast has helped to mitigate attacks on the root server system where the attack became limited in scope to certain Anycast instances of the root server and caused a saturation of network connections.
On the contrary, Mirai botnet attack on Dyn Infrastructure also tells us that large scale attack can cause congestion across the Anycast instances resulting in unavailability of services.
Finally, we get to a set of broader questions – How do we increase resiliency against a DDoS on the root server system ? Since the root server system doesn’t penalise abuse (period), should we continue abusing it ?
A probable solution as proposed in RFC 7706 is to run a local copy of the full root zone on the loopback. What this essentially suggests is that the full root zone on the loopback will serve as upstream to the recursive resolver and the recursive resolver should be able to validate the zone from the upstream using DNSSEC.
In order to implement this, one first needs a copy of the root zone. The following root servers currently allow transfer of the root zone using AXFR over TCP,
Root Server Operators which support transfer of the root zone
The process of manually pulling the root zone has an operational issue – one needs to periodically check if the root zone has changed in the root zone copy at the upstream and then update the copy of the root zone configured to run on the loopback.
Even though RFC 7706 is Informational, recursive resolver software such as ISC BIND, Unbound, Knot Resolver have built-in support.
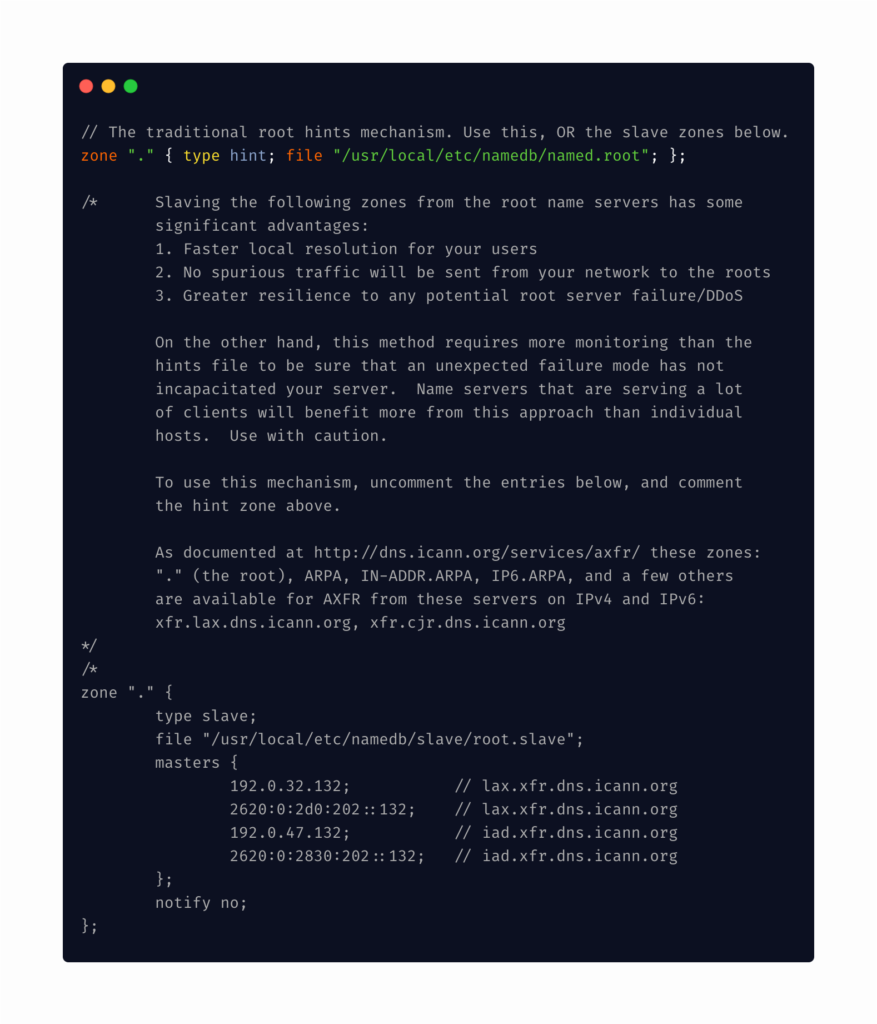
Slaving of the root zone – ISC BIND 9.16.3(stable)
Image of an excerpt from named.conf showing the slaving of the root zone configuration
Part II of this post will contain operational instructions for running a local copy of the root zone and document some of the pitfalls of doing so.
DNS root servers are the heart of the DNS infrastructure. Although there are just 13 of them, the actual number comprises of 1084 instances in Anycast operated by 12 independent root server operators.
A recent study by ICANN OCTO on Analysis of the Effects of COVID-19-Related Lockdowns on IMRS Traffic shed some light on DNS traffic patterns before COVID-19 and during. While the study looked at the ICANN Managed Root Server Instance (IMRS) i.e a few instances of the L-Root Server ( l.root-servers.net), I wouldn’t be surprised if the pattern is similar for other root servers as well.
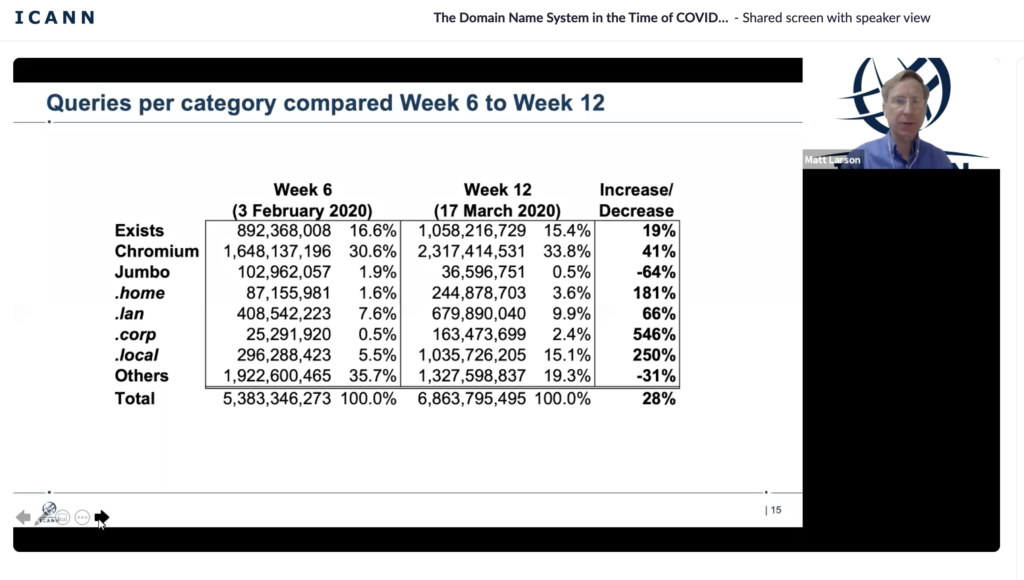
One stark observation in the study was the amount of DNS traffic for non-existent TLDs. As every DNS transaction begins with a query to the root server and goes down the delegation chain, queries for non-existent records are also sent to the root servers.
Topping the chart is browsers based on Chromium. Not surprising since Chromium based browsers send a 7-15 character three random strings on startup to check if the browser is sitting behind captive portal. Check my earlier blog post Chromium based browsers & DNS for more information on the topic.
So, I had sent in a question to the Ask Mr. DNS podcast asking if they knew if there was a formal specification/guidelines for consequences of excessively abusing the root servers. And guess what,
I would urge you to listen to the entire episode as it contains juicy bits by Kim Davies about the Root Key Signing Key Ceremony, but if you’re the impatient lot & !DNS Geek, skip to 31:48 to tune in for my few seconds of fame 😀
While this is not something new, it perhaps has more significance because of the ever increasing market share of more than 60% of Chromium based browsers.
Chromium based browsers have a very uncanny method to check if the web browser is sitting behind a captive portal. And if you’re running a recursive resolver in your network with a large user base running Chromium based browsers (Google Chrome, Brave etc), it might even startle you if you observe the recursive resolver logs.
Here is a snippet from my unbound resolver as soon as I start Google Chrome on the machine(192.168.0.188),
Jun 3 11:16:31 root unbound: [1283:0] info: 192.168.0.188 pwpsfrn. A IN
Jun 3 11:16:31 root unbound: [1283:0] info: 192.168.0.188 yeytluindg. A IN
Jun 3 11:16:31 root unbound: [1283:0] info: 192.168.0.188 zkgtcrxrpfjcjxr. A IN
A research project at USC What’s In A Name? goes into some detail with the classification.
Here is the summary of the study,
Though the root server system handles this application-specific load sufficiently, it is clear that Chrome’s trick of using randomly generated names to discover whether it’s behind a captive portal contributes significantly to the traffic received at the root zone.